AI系列之NPU:专为端侧AI而生的神经网络加速器-中泰电子
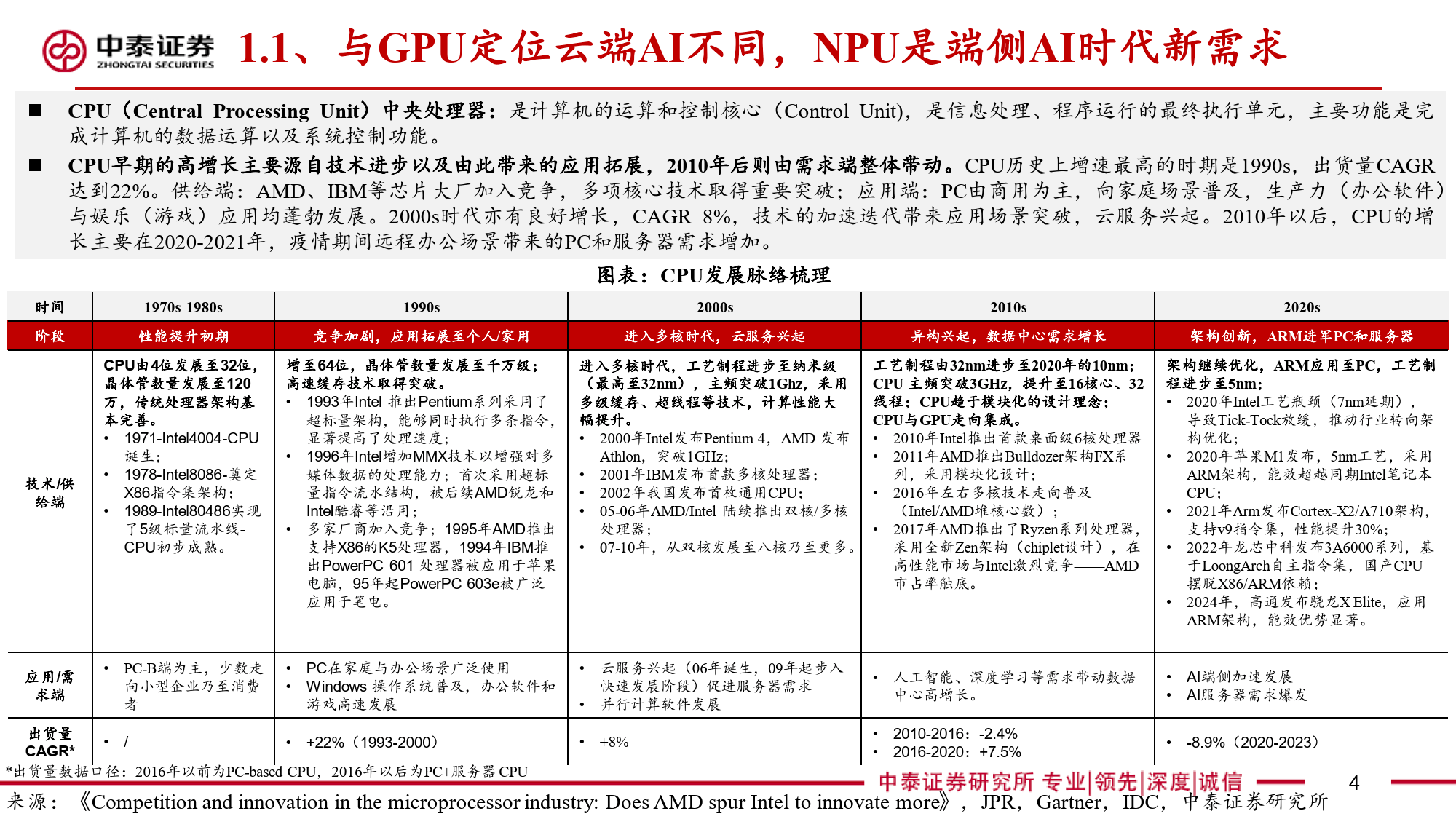
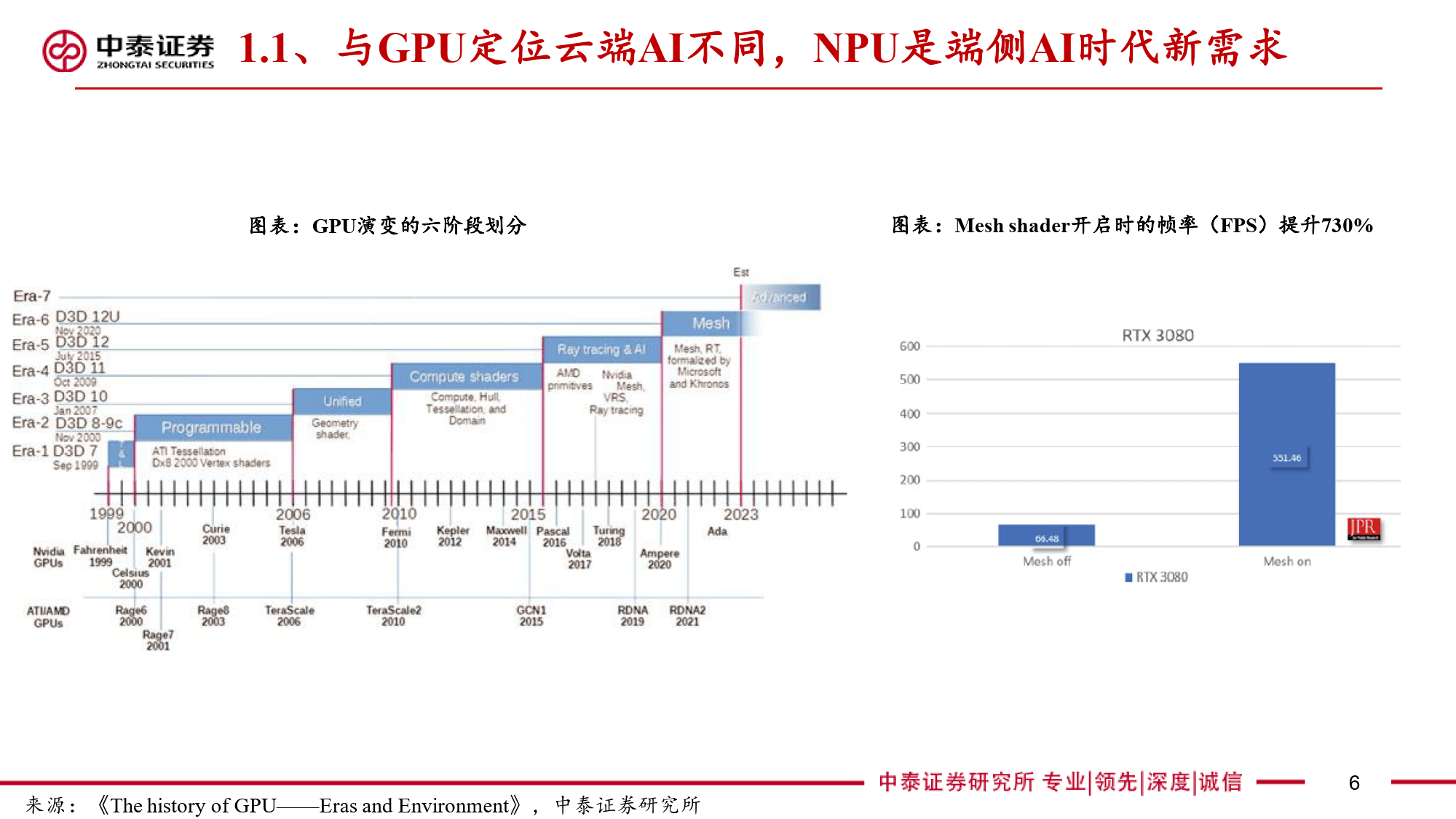
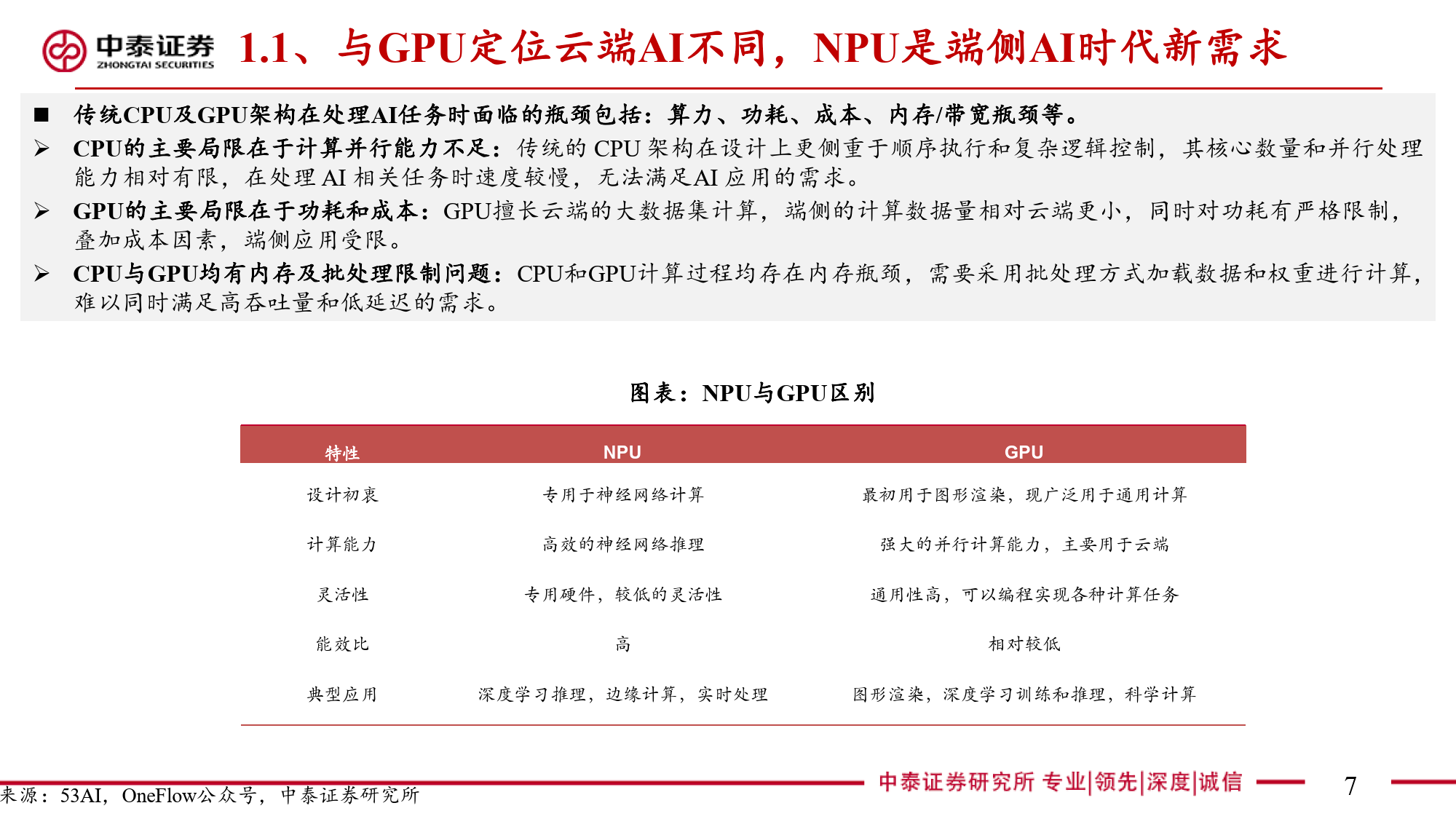
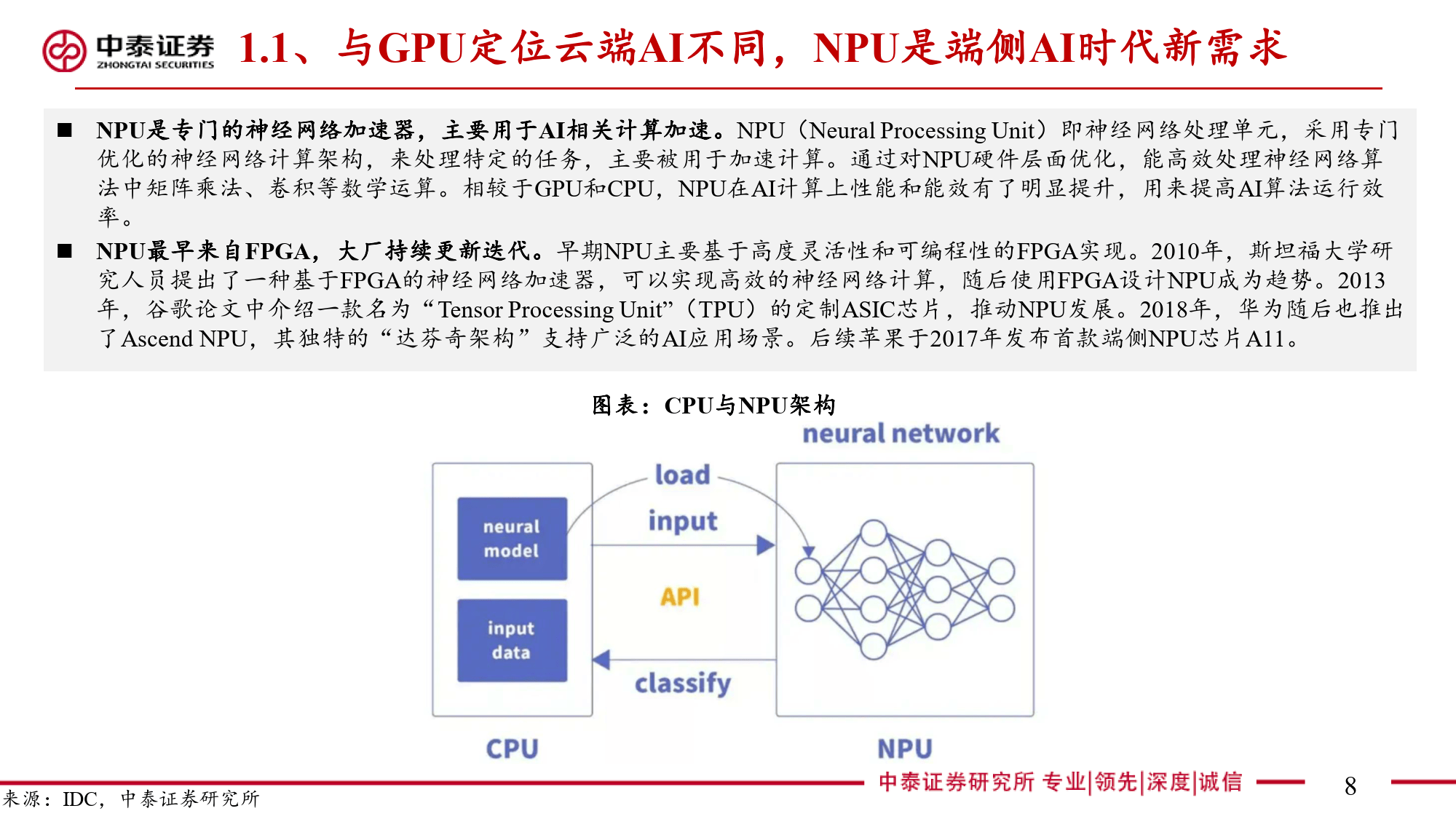
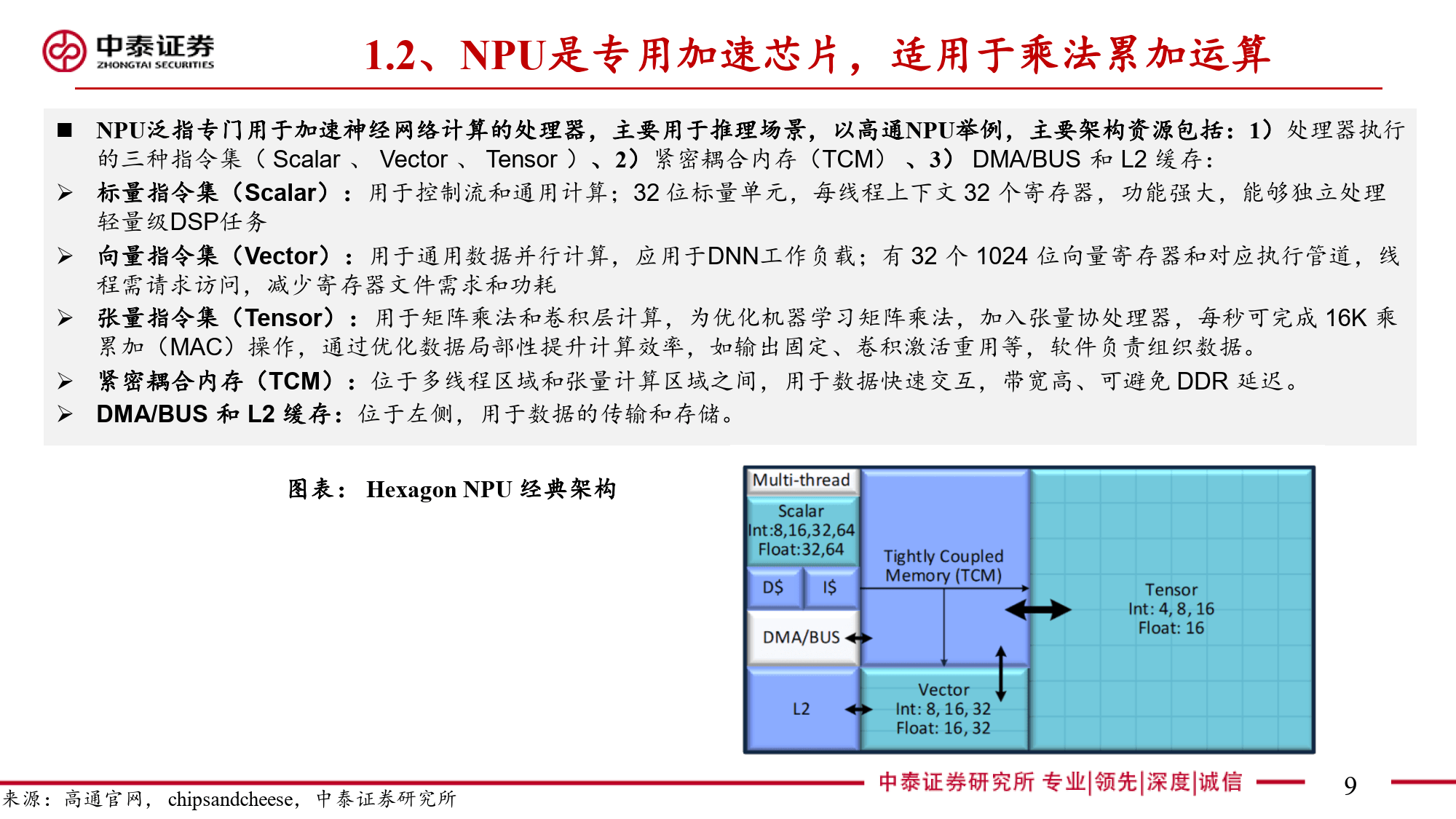
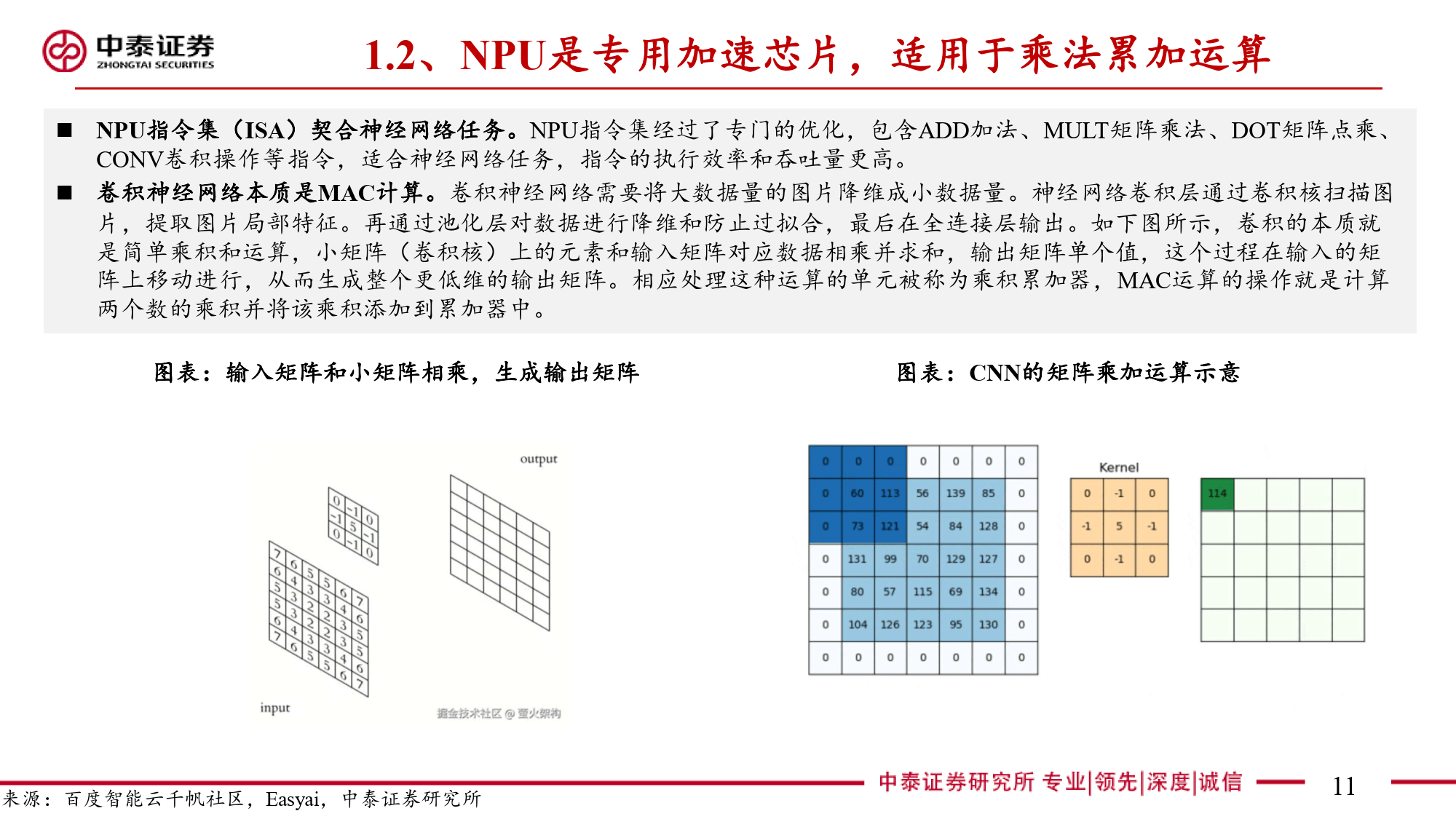
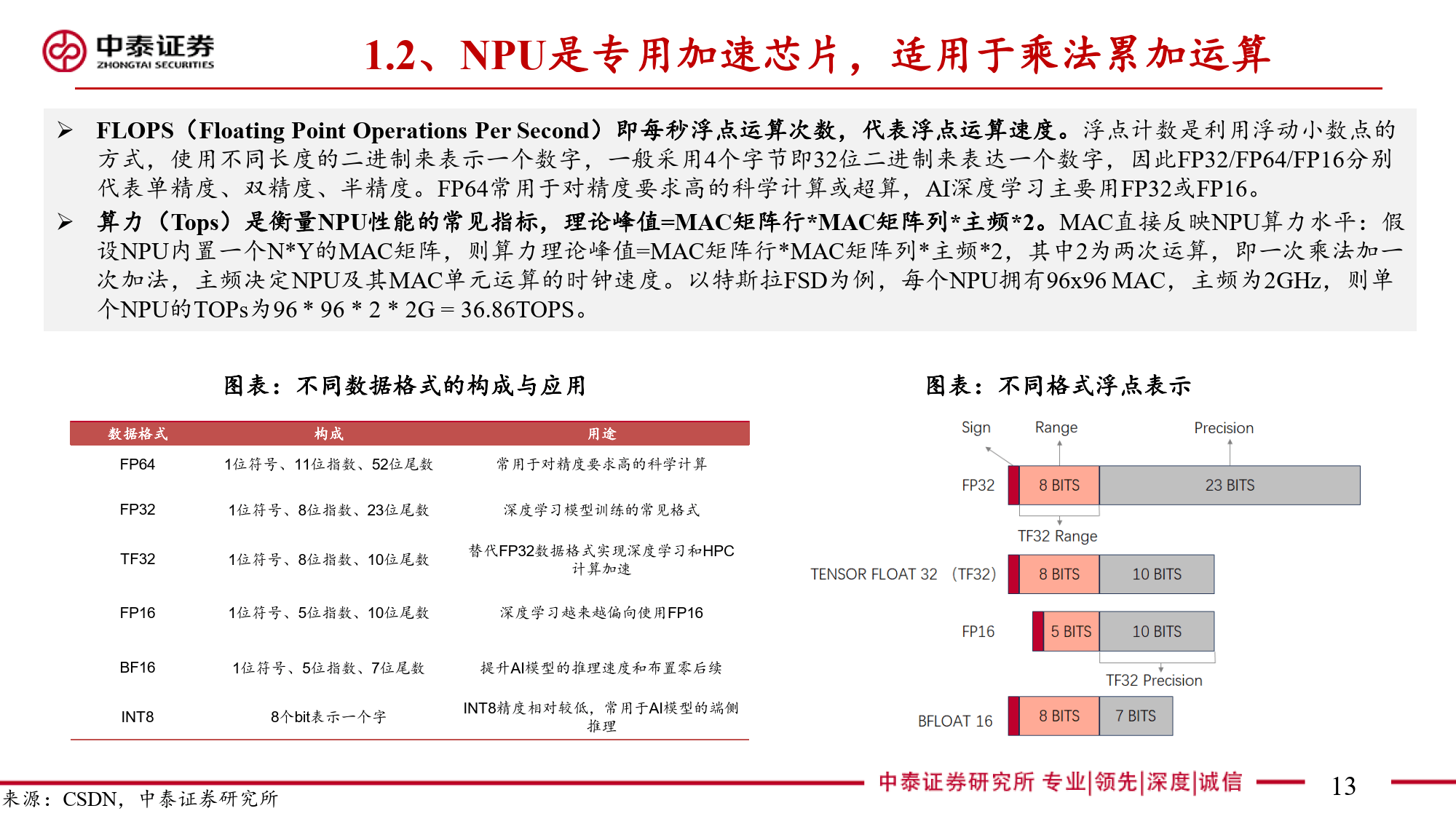
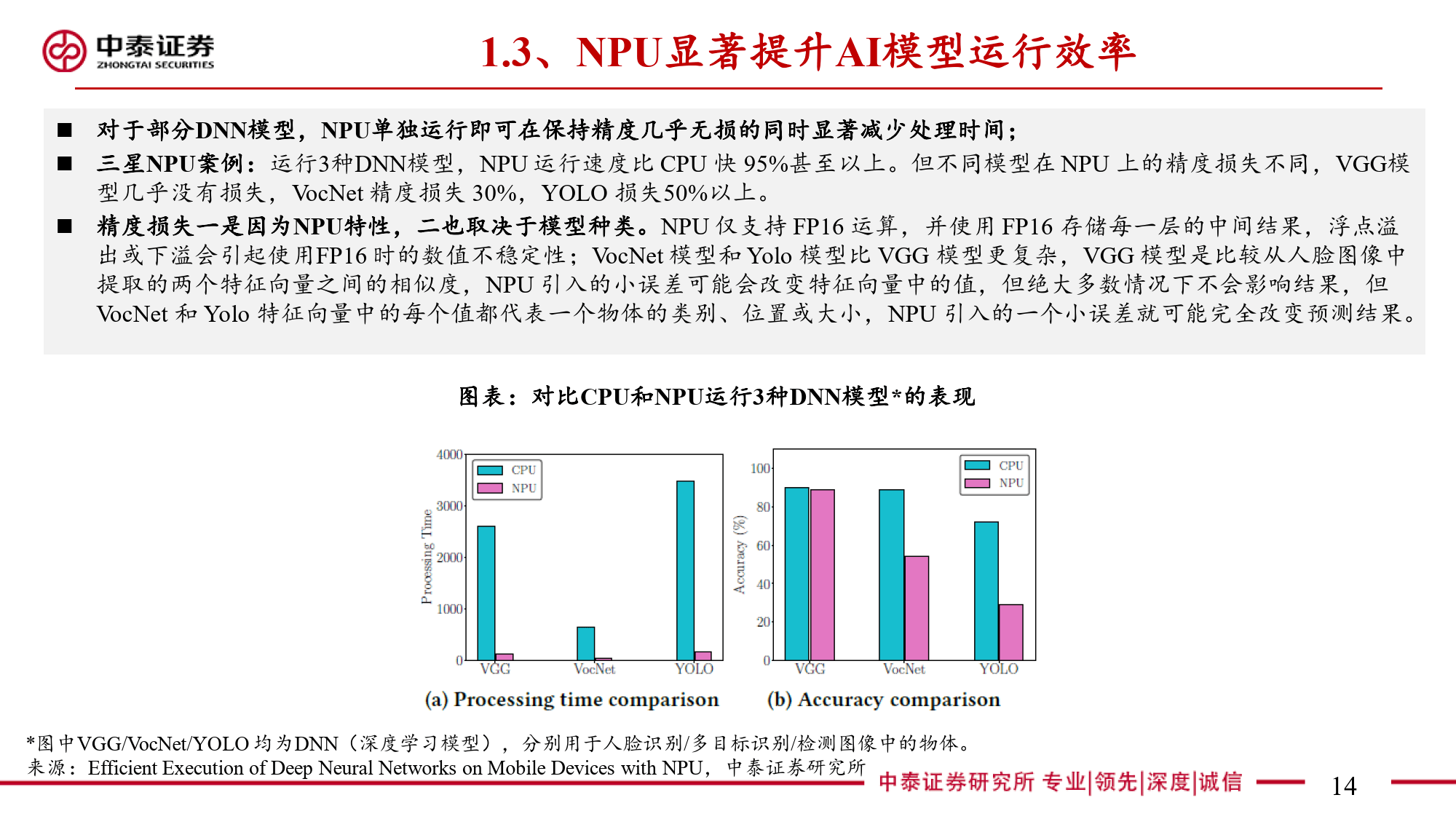
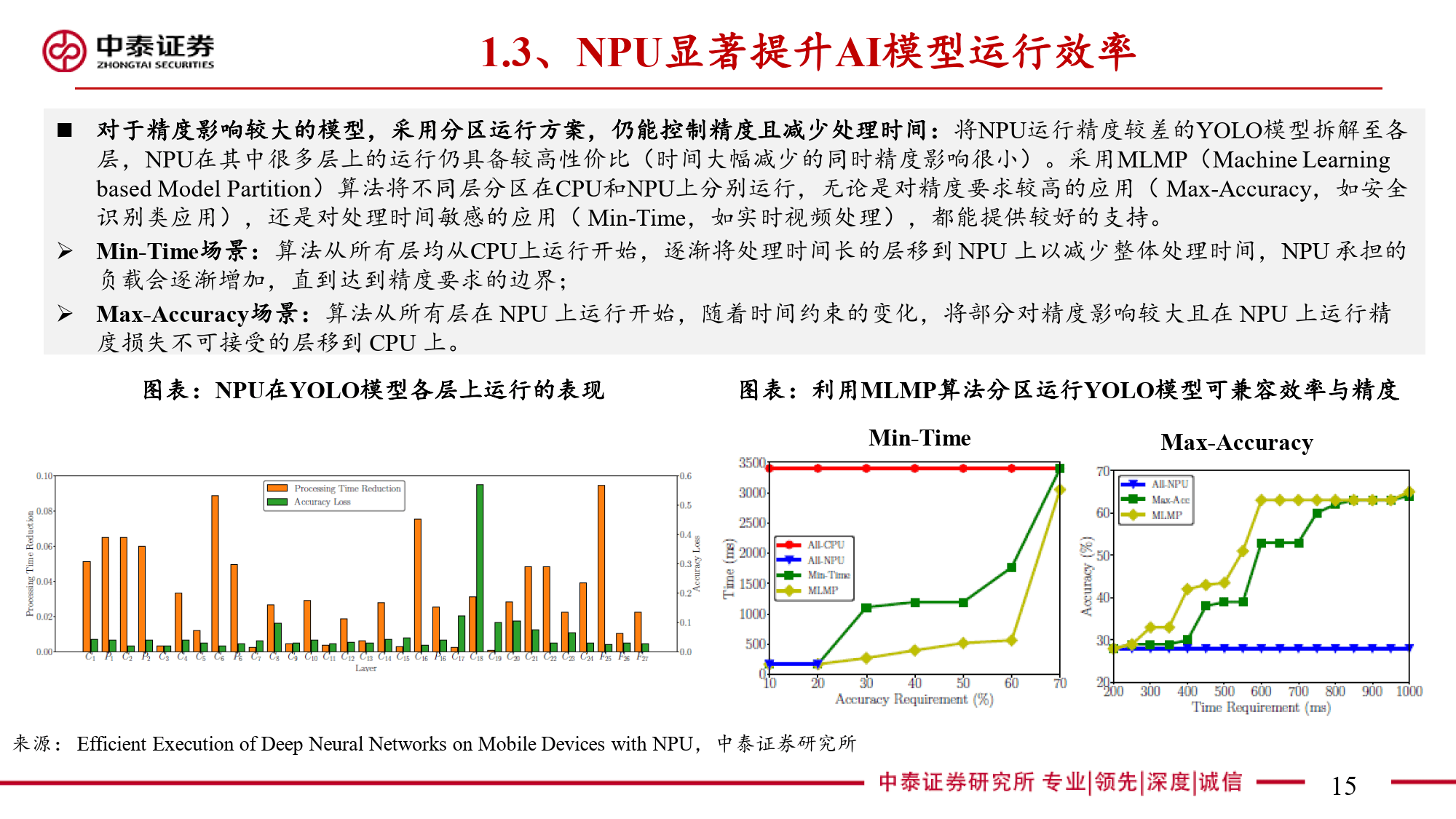
本报告全面剖析了NPU(神经网络处理器)这一端侧AI关键芯片的多维度信息。NPU作为专为端侧AI设计的神经网络加速器,与云端AI的GPU存在显著差异。在AI任务处理中,CPU因擅长顺序执行和复杂逻辑控制存在瓶颈,GPU虽侧重并行计算但在端侧场景中能效受限。NPU通过采用源于FPGA并经大厂迭代优化的神经网络计算架构,以矩阵乘法运算为核心,利用MAC单元高效处理AI算法中的数学运算。其算力以TOPS为衡量单位,在运行部分DNN模型时可大幅减少处理时间,针对复杂模型则采用分区运行方案平衡精度与效率。
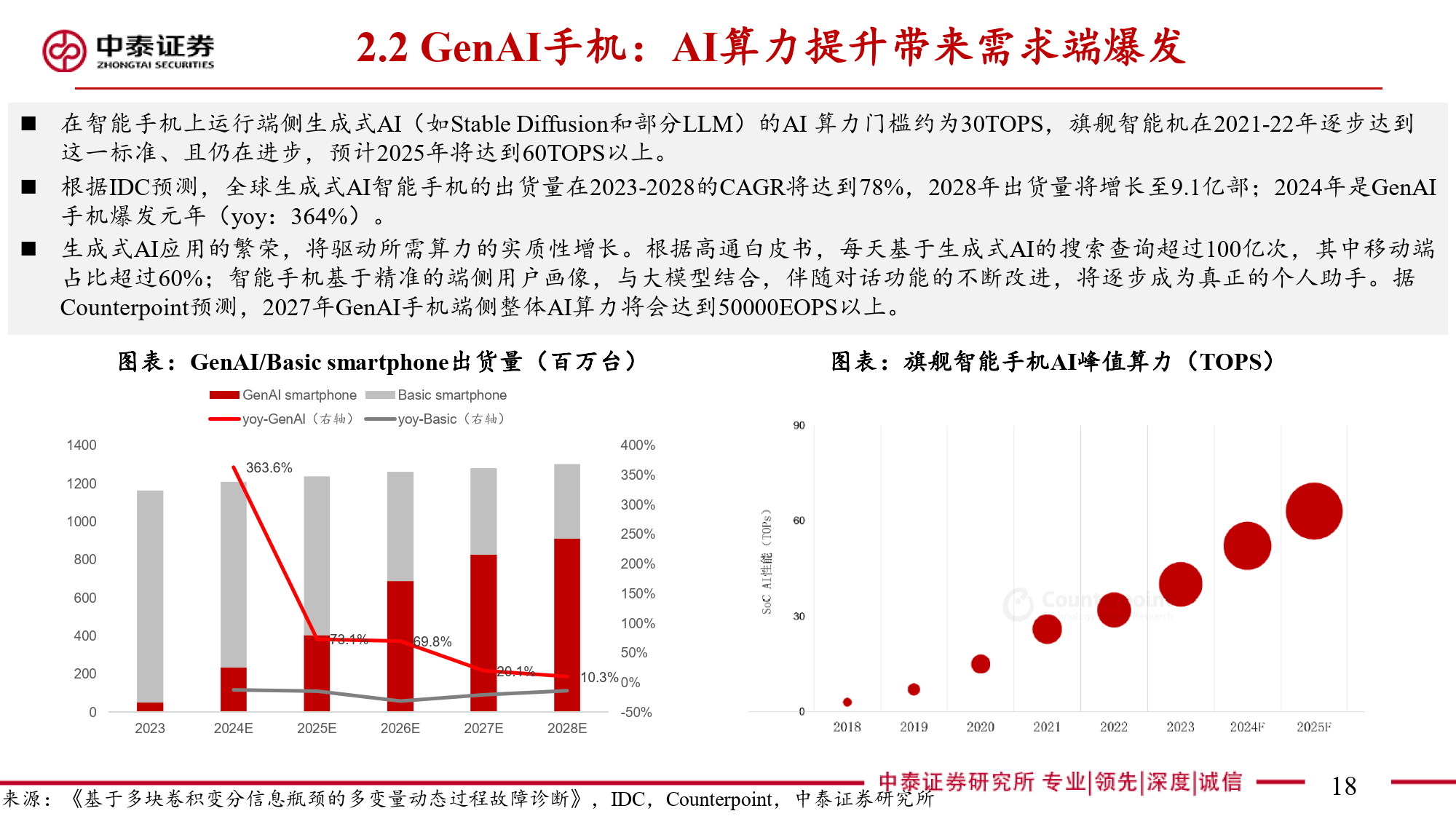
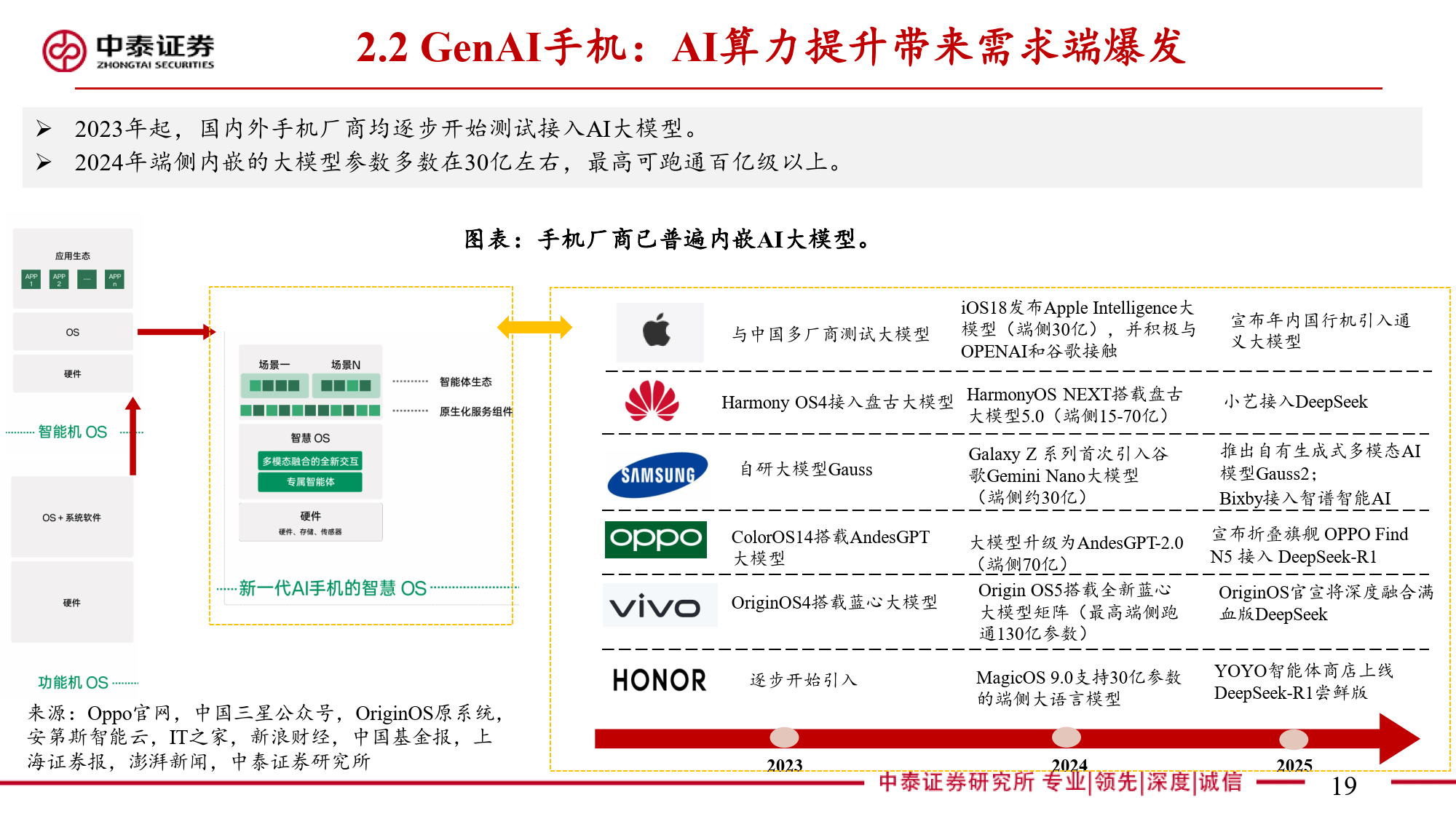
随着AI技术的迅猛发展,NPU的端侧应用场景呈现爆发式增长。从早期的音频语音AI拓展至支持百亿级参数的大语言和大视觉模型,NPU在消费电子领域的应用尤为突出。GenAI手机的全球出货量快速增长,手机厂商纷纷接入大模型,使NPU成为核心AI工作负载承担者。AI PC的渗透率迅速攀升,NPU作为其关键加速器,其算力在主流PC芯片中的占比逐渐提高。在智能驾驶领域,全球智能驾驶乘用车渗透率快速攀升,汽车因GenAI模型应用对端侧算力的需求进一步提升,高通等厂商推出的车载芯片已集成NPU以满足这一需求。此外,机器人产业的快速发展使NPU在机器人中用于加速计算、实现实时交互和决策,例如宇树科技的机器狗已采用"国产6T芯片"实现智能功能。
在产业趋势方面,存算一体技术正成为解决NPU计算瓶颈的关键路径。近存计算通过封装技术拉近存储与计算单元的距离,已实现商业化应用,如HBM和3D堆叠DRAM等技术。存内处理则在存储单元内增加计算单元,而存内计算实现了存储与计算单元的完全融合,尽管目前商业化难度较大。WOW 3D堆叠DRAM作为近存计算的代表,采用3D堆叠工艺,具备高带宽、低功耗的特点,适用于AI低算力场景的存储需求。在厂商布局方面,高通作为NPU研发的先驱,其架构不断迭代,算力持续提升,已广泛应用于多终端场景。三星通过算法优化和MAC集成提升NPU性能,第四代产品在算力和能效方面取得显著进步。Intel近两年加快NPU迭代速度,增加计算引擎数量和内存带宽,使其在AI PC中的算力占比逐渐提高。多数移动SoC采用集成NPU设计,具备共享缓存和降低能耗的优势;而分立NPU则因易于扩展,适用于汽车和工业等对扩展性要求较高的端侧AI工作负载。华为昇腾的达芬奇架构以高算力、高能效著称,应用范围广泛。瑞芯微作为国产端侧NPU的龙头企业,不断升级产品以赋能多场景AIoT设备。此外,晶晨股份、全志科技等国产厂商也在加速布局端侧NPU,积极卡位AIoT市场。报告最后提供了相关投资建议与风险提示,为投资者把握NPU产业机遇提供了重要参考。