豆包大模型Seedream2
今天分享的是:豆包大模型Seedream2
报告共计:33页
《Seedream 2.0:一个原生中文 - 英文双语图像生成基础模型》由字节跳动Seed Vision团队撰写。文章介绍了Seedream 2.0这一先进的双语文本到图像扩散模型,旨在解决当前图像生成系统存在的问题,提升图像生成质量与性能。
1. 研究背景与目的:扩散模型推动图像生成发展,但主流模型存在模型偏见、文本渲染能力不足和对中文文化理解欠缺等问题。Seedream 2.0旨在解决这些问题,实现双语图像生成和文本渲染,生成高质量图像。
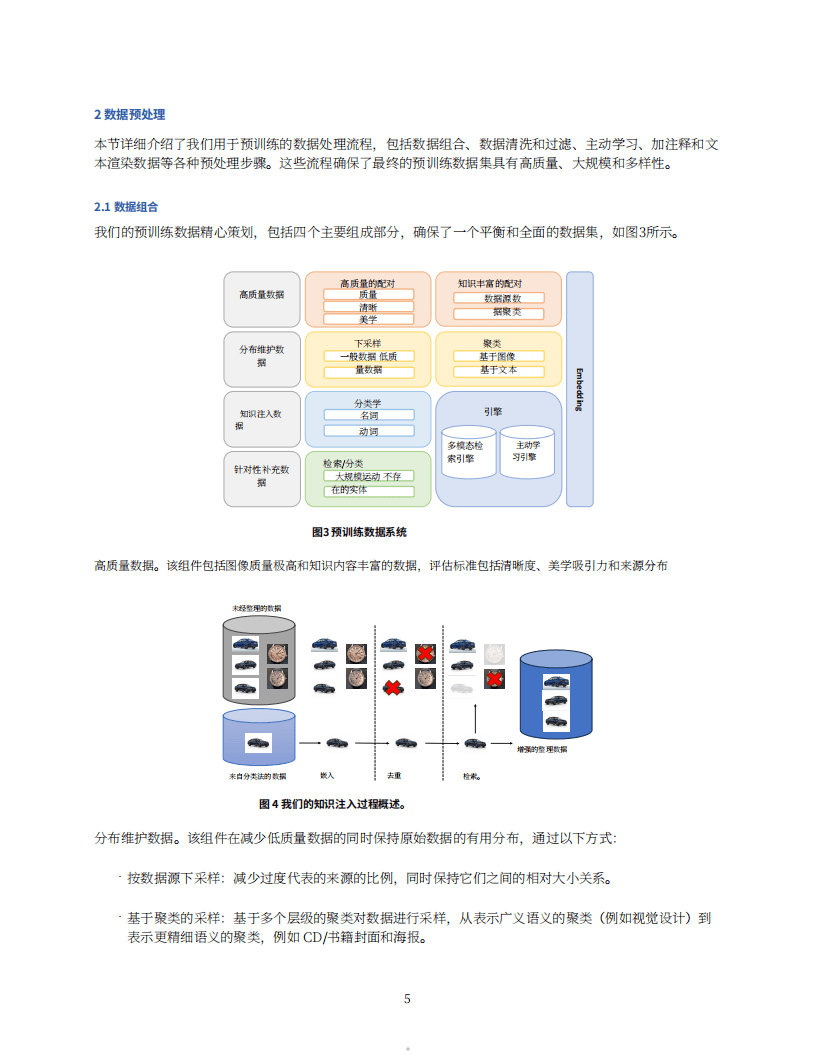
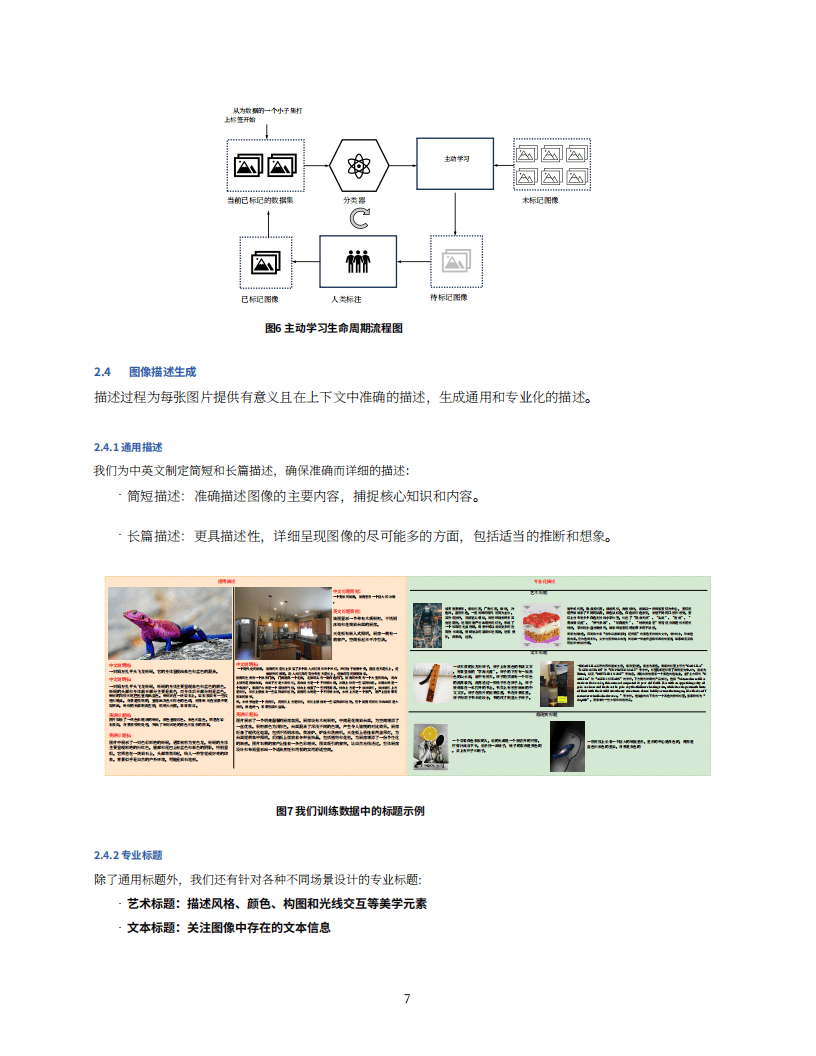
2. 数据预处理:精心规划预训练数据,包括高质量数据、分布维护数据、知识注入数据和针对性补充数据。通过多阶段数据清理确保数据质量,利用主动学习引擎改善图像分类器。为图像生成通用和专业标题,构建文本渲染数据集。
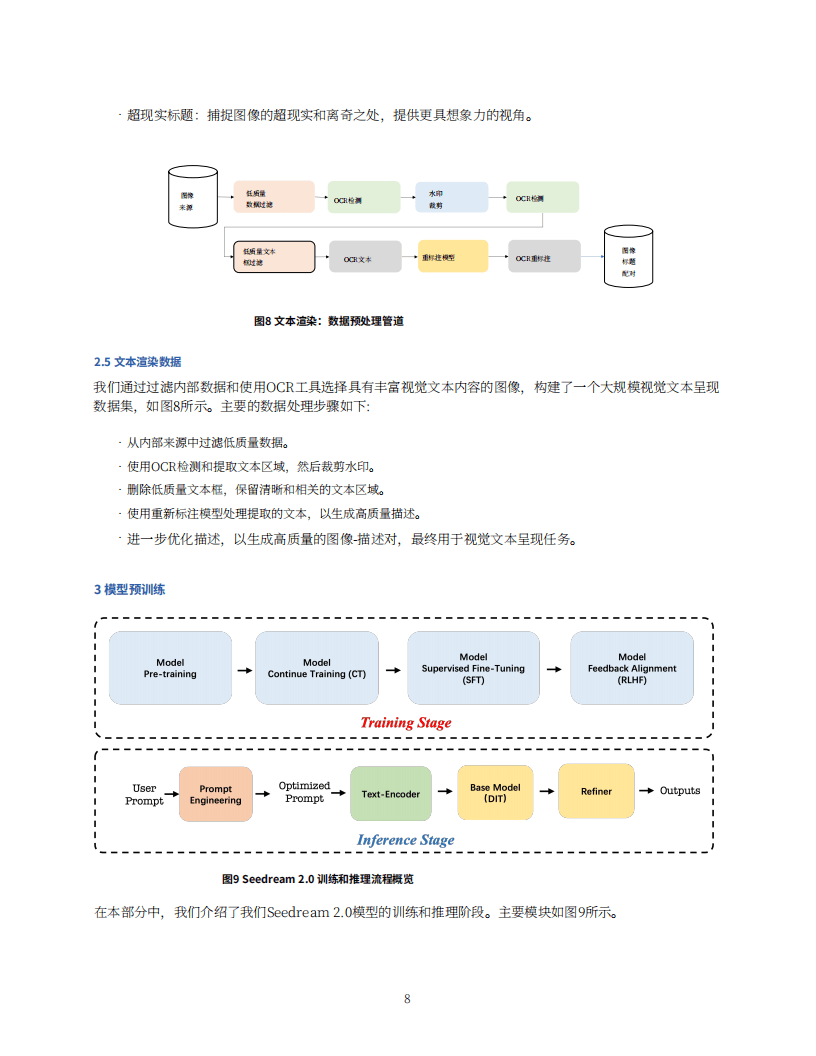
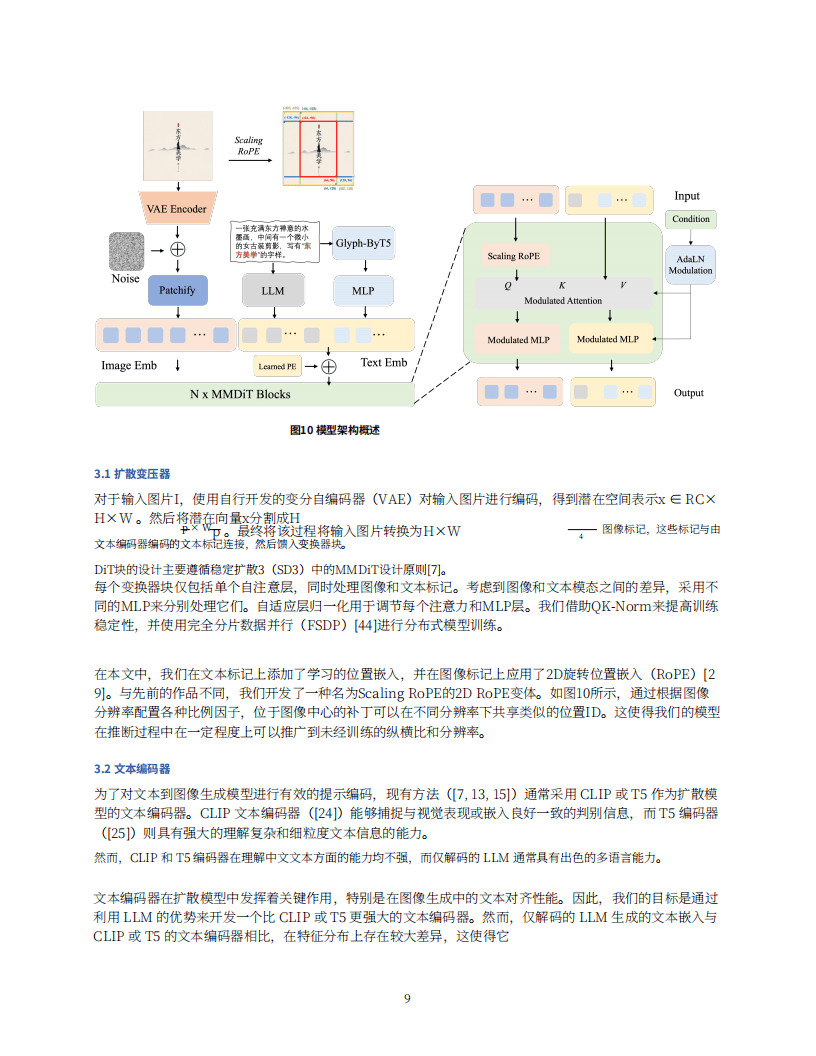
3. 模型架构与训练:扩散变压器采用VAE编码图片,基于SD3的MMDiT设计,添加位置嵌入并使用Scaling RoPE推广到未训练分辨率。文本编码器利用LLM优势,通过微调解决与图像表示对齐问题,增强双语能力。字符级文本编码器结合LLM和ByT5模型,提升文本渲染效果。模型后训练通过持续训练、监督微调、人类反馈对齐、提示工程和精炼器等步骤,提升模型性能。
4. 模型应用与优化:将模型改编为基于指令的图像编辑模型SeedEdit,通过新的数据生成过程、因果扩散框架和训练策略,提升图像编辑质量,并增强人脸识别能力。采用引导比例嵌入和步骤蒸馏、量化等技术,提高模型推理效率。
5. 模型性能评估:通过人类评估和自动评估,对比其他SOTA模型,结果显示Seedream 2.0在中英文提示下表现出色,在文本 - 图像对齐、美学质量、结构正确性、文本渲染和中文特征等方面优势明显。
6. 研究结论:Seedream 2.0通过创新设计和优化,有效解决了现有图像生成模型的局限,在多方面性能卓越,在实际应用中获得广泛赞誉,为图像生成领域发展提供了有力支持。
以下为报告节选内容






报告共计: 33页
中小未来圈,你需要的资料,我这里都有!


